本文最后更新于 3 分钟前,文中所描述的信息可能已发生改变。
Java 基础
基本类型和包装类型
基本类型和包装类型的种类(8 种)
- 基本类型:byte、short、int、long、float、double、char、boolean。
- 包装类型:Byte、Short、Integer、Long、Float、Double、Character、Boolean。
基本类型和包装类型的区别?
- 用途:除了定义一些常量和局部变量之外,我们在其他地方比如方法参数、对象属性中很少会使用基本类型来定义变量。并且,包装类型可用于泛型,而基本类型不可以。
- 存储方式:基本数据类型的局部变量存放在 Java 虚拟机栈中的局部变量表中,基本数据类型的成员变量(未被 static 修饰 )存放在 Java 虚拟机的堆中。包装类型属于对象类型,我们知道几乎所有对象实例都存在于堆中。
- 占用空间:相比于包装类型(对象类型), 基本数据类型占用的空间往往非常小。
- 默认值:成员变量包装类型不赋值就是 null ,而基本类型有默认值且不是 null。
- 比较方式:对于基本数据类型来说,== 比较的是值。对于包装数据类型来说,== 比较的是对象的内存地址。所有整型包装类对象之间值的比较,全部使用 equals() 方法。
浮点数运算的精度问题?
答:浮点数运算的精度问题是由于浮点数的二进制表示方式导致的。 浮点数在计算机中是以二进制的形式存储的,而二进制无法精确表示某些十进制小数,比如 0.1。 所以在计算机中,0.1 会被近似表示为一个无限循环小数。这就导致了浮点数运算的精度问题。 解决方法:可以使用 BigDecimal 类来解决浮点数运算的精度问题。
String 为什么不可变?
- 通过使用 final 关键字,String 类可以被设计成不可变的。
- 不可变的字符串有利于字符串常量池的实现,提高字符串的共享性和安全性。
- 字符串常量池位于方法区,存储字符串常量。
String,StringBuffer,StringBuilder 的区别?
- String 是不可变的字符串,每次修改都会生成新的字符串对象,适用于字符串不经常变化的场景。
- StringBuffer 是线程安全的可变字符串,适用于多线程场景。
- StringBuilder 是非线程安全的可变字符串,适用于单线程场景。
面向对象
面向对象(Object-Oriented Programming, OOP)是 Java 的核心编程范式,通过定义类和对象来组织程序。主要概念包括:
- 类:描述一组具有相同属性和行为的对象的模板。
- 对象:类的实例,具有状态和行为。
- 封装:通过将数据和方法封装在类中,控制访问权限,提高安全性和可维护性。
- 继承:通过继承父类,子类可以重用父类的属性和方法,并且可以扩展或重写父类的方法。
- 多态:通过接口或继承实现不同对象以统一的方式被调用的能力,具体执行方法由实际对象类型决定。
面向对象的三大特征是什么?
答:封装、继承、多态。
重载与重写
反射
异常
IO
注解
@RestController 和@Controller 的区别
答:@RestController 是 Spring4 之后加入的注解,是@ResponseBody 和@Controller 的组合注解,用于返回 json 数据。 @Controller 是 SpringMVC 的注解,用于标识控制器类。
@Autowired 和@Resource 的区别
@Autowired 是 Spring 的注解,按类型注入,@Resource 是 J2EE 的注解,按名称注入。
JAR (Java Archive)
打包成 jar 包之后这些**依赖包**的位置在哪呢,java 是怎么识别的?
在我的项目配置,项目中使用maven来管理依赖和打包,在编译后,会打包到./target/,java是通过classpath来识别依赖的。
- 普通打包:
java -cp xxx.jar:lib/* com.example.demo.DemoApplication,需要使用-cp指定依赖包的位置。 - spring-boot-maven-plugin 打包:
java -jar ***.jar,spring-boot-loader 会自动识别BOOT-INF/lib下的依赖包。
JVM (Java Virtual Machine)
JVM 的组成部分有那些?
- 类加载器(ClassLoader):负责将字节码文件加载到运行时数据区。只负责加载字节码文件,不负责验证字节码文件。
- 运行时数据区(Runtime Data Area):包括方法区、堆、栈、本地方法栈、程序计数器等。
- 执行引擎(Execution Engine):负责执行字节码文件。将字节码文件解释为机器码执行。
- 本地方法接口(Native Interface):调用本地接口。
内存结构
内存模型 (JMM)
详见 helltractor blog 中Java Memory Model
垃圾回收 (GC)
详见 helltractor blog 中Garbage Collect
类加载机制
自定义java.lang.String类,能否使用?
- 可以自定义包名不为java.lang的String类,并区别包名正常使用
- 自定义包名为java.lang的String类
- String类下写main方法:由于双亲委派模型,在加载String类时,会最终委派给Bootstrap ClassLoader去加载,加载的是rt.jar包中的那个java.lang.String,而rt.jar包中的String类是没有main方法的,因此报错误
- 启动类也在java.lang包下:这里与是否用到String类无关,会报 Prohibited package name: java.lang错误。由于双亲委派,java.lang 包肯定早于自定义的java.lang 包的加载,就会冲突.
- 调用方法不在java.lang包中:此时由于双亲委派模型的存在,并不会加载到自定义的String类
关于作者
- 来自一线程序员Seven的探索与实践,持续学习迭代中~
- 本文已收录于我的个人博客:https://www.seven97.top
- 公众号:seven97,欢迎关注
类加载器
什么是类加载器?
类加载器(ClassLoader)是 Java 虚拟机(JVM)的一部分,用于将字节码文件加载到 JVM 运行时数据区中。 现有的类加载器基本都是 java.lang.ClassLoader 的子类,该类用于将指定的类找到或生成对应的字节码文件。 同时,类加载器负责加载程序所需的资源文件。
有哪些类加载器?
- 启动类加载器(Bootstrap ClassLoader):不继承 ClassLoader。用于加载 JVM 运行时必备的核心类,如 JAVA_HOME/jre/lib 目录下的类。
- 扩展类加载器(Extension ClassLoader):加载 JVM 扩展目录中的类,如 JAVA_HOME/jre/lib/ext 目录中的类。
- 应用程序类加载器(Application ClassLoader):加载应用程序 classpath 目录中的类。
- 自定义类加载器:继承 ClassLoader 类,实现自定义类加载规则。
双亲委派模型 (Parent Delegation Model)
什么是双亲委派模型?
每个类加载器在尝试加载类或资源时,会首先检查请求加载的类型是否已经被加载过,若没有将这个任务委托给它的父加载器去完成。 只有当父加载器无法找到并加载请求的类时,子加载器才会尝试自己去加载该类。
双亲委派模型的优点?
- 避免类的重复加载:当父加载器已经加载了一个类时,子加载器不会再加载一次。
- 避免恶意代码:防止恶意代码替换 JDK 中的核心类。
如何破坏双亲委派模型?
- 重写 loadClass()方法:重写 loadClass()方法,让当前 ClassLoader 先尝试加载类。
- 重写 findClass()方法:findClass() 只会被 loadClass() 调用,不会委派给父类。重写 findClass()方法,自定义加载规则。
- 使用线程上下文类加载器:通过 Thread.currentThread().setContextClassLoader()设置线程上下文类加载器。 临时替换当前线程的类加载器,使得类加载器不再遵循双亲委派模型。如:Tomcat 的 Web 应用程序类加载器就是通过线程上下文类加载器实现的。
JUC (java.util.concurrent)
并发编程允许程序同时执行多个任务,提高程序效率。Java 通过多线程实现并发。主要类和接口包括:
- Thread 类:表示线程的类,通过继承 Thread 类来创建线程。
- Runnable 接口:表示任务的接口,通过实现 Runnable 接口来创建线程。
- Callable 接口:表示有返回值的任务的接口,通过实现 Callable 接口来创建线程。
- Executor 框架:用于管理线程池和任务调度,如 ExecutorService、ThreadPoolExecutor。
volatile 关键字的作用是什么?
volatile 是 Java 提供的一种轻量级的同步机制,它具有两个特性:可见性和有序性。
- 可见性:volatile 保证了线程间变量是可见的,即当一个线程修改了共享变量后,该变量会立马同步到主内存,其余线程监听到数据变化后会使得自己缓存的原数据失效,并触发 read 操作读取新修改的变量的值。
- 有序性:volatile 保证了线程对变量的修改是有序的,即禁止指令重排序。
- 当程序执行到 volatile 变量的读操作或者写操作时,在其前面的操作的更改肯定全部已经进行,且结果已经对后面的操作可见,在其后面的操作肯定还没有进行。
- 在进行指令优化时,不能将在对 volatile 变量访问的语句放在其后面执行,也不能把 volatile 变量后面的语句放到其前面执行。
- 应用场景
- volatile 不能保证原子性,即不能保证多个线程同时修改一个变量时的线程安全性。
- volatile 不能代替锁,它只能保证可见性和有序性,不能保证原子性。
- volatile 适用于一个线程写,多个线程读的场景。
多线程的几种实现方式?
- 继承 Thread 类
public class MyThread extends Thread {
@Override
public void run() {
// ...
}
}- 实现 Runnable 接口
public class MyRunnable implements Runnable {
@Override
public void run() {
// ...
}
}- 实现 Callable 接口
public class MyCallable implements Callable<Integer> {
@Override
public Integer call() throws Exception {
// ...
return 0;
}
}- 使用线程池
ExecutorService executor = Executors.newFixedThreadPool(10);
executor.execute(new MyRunnable());
Future<Integer> future = executor.submit(new MyCallable());多线程实现方式的区别?
| 方式 | 是否支持返回值 | 是否可复用 | 应用场景 |
|---|---|---|---|
| 继承 Thread 类 | 不支持 | 不可复用 | 简单场景 |
| 实现 Runnable 接口 | 不支持 | 可复用 | 多线程共享资源 |
| 实现 Callable 接口 | 支持 | 可复用 | 需要返回值的任务 |
| 使用线程池 | 支持 | 可复用 | 高并发场景 |
锁机制
乐观锁与悲观锁的区别?
- 悲观锁基于悲观的假设,认为共享资源在每次访问时都会发生冲突,因此在每次操作时都会加锁。 这种锁机制会导致其他线程阻塞,直到锁被释放。Java 中的 synchronized 和 ReentrantLock 是悲观锁的典型实现方式。 虽然悲观锁能有效避免数据竞争,但在高并发场景下会导致线程阻塞、上下文切换频繁,从而影响系统性能,并且还可能引发死锁问题。
- 乐观锁基于乐观的假设,认为共享资源在每次访问时不会发生冲突,因此无须加锁,只需在提交修改时验证数据是否被其他线程修改。 Java 中的 AtomicInteger 和 LongAdder 等类通过 CAS(Compare-And-Swap)算法实现了乐观锁。 乐观锁避免了线程阻塞和死锁问题,在读多写少的场景中性能优越。但在写操作频繁的情况下,可能会导致大量重试和失败,从而影响性能。
- 著作权归JavaGuide(javaguide.cn)所有
- 基于MIT协议
- 原文链接:https://javaguide.cn/java/concurrent/optimistic-lock-and-pessimistic-lock.html
公平锁与非公平锁的区别?
- 公平锁:按照线程请求的顺序来获取锁,即先到先得。
- 非公平锁:不考虑线程请求的顺序,有可能后请求的线程先获取到锁。
CAS (Compare And Swap)
- 定义:CAS 是一种乐观锁,通过比较当前值和期望值是否一样来决定是否更新。
- 相关类:AtomicInteger、AtomicLong、AtomicReference 等。
- 相关问题
| 问题 | 解决方案 |
|---|---|
| ABA 问题 | 使用版本号或时间戳解决,如 AtomicStampedReference |
| 循环时间长开销大 | 限制重试次数,避免无限循环,如自旋锁 |
| 只能保证一个共享变量的原子操作 | 使用 AtomicReference 或加锁 |
ABA 问题:线程 1 读取数据 A,线程 2 将 A 改为 B,再改回 A,线程 1 再次读取 A,认为 A 未变化。
synchronized
- 定义:synchronized 是一种悲观锁,通过获取锁来保证同一时刻只有一个线程执行。
- 特点:可重入、非公平锁、不可中断、性能高。
- 使用场景:适用于代码块同步、单例模式、简单场景。
ReentrantLock
- 定义:ReentrantLock 是一种可重入锁,通过 AQS 实现。
- 特点:支持公平/非公平锁、可中断、超时获取。
- 使用场景:适用于复杂场景,如高并发、需要公平锁、可中断、超时获取或多个条件变量等场景。
synchronized 和 ReentrantLock 的区别,具体使用场景,注意事项?
- 区别
| 对比项 | synchronized | ReentrantLock |
|---|---|---|
| 底层实现 | JVM 内置,基于 Monitor | JDK 提供的 API,基于 AQS(AbstractQueuedSynchronizer) |
| 锁类型 | 悲观锁,只能独占(排他锁) | 支持公平/非公平锁、可中断、超时获取 |
| 可重入性 | ✅ 支持 | ✅ 支持 |
| 公平性 | ❌ 非公平 | ✅ 支持公平锁和非公平锁 |
| 锁的范围 | 作用在方法或代码块 | 灵活,作用于任意代码块 |
| 是否可中断 | ❌ 不可中断 | ✅ 可以中断 lockInterruptibly() |
| 是否可超时 | ❌ 不支持超时获取锁 | ✅ tryLock(timeout) 支持超时等待 |
| 是否需要手动释放 | ❌ 自动释放(异常时也会释放) | ✅ 需要 lock() 和 unlock() 手动释放 |
| 性能 | JVM 内部优化,性能高 | 适用于复杂场景,但开销稍大 |
- 使用场景
- synchronized:适用于代码块同步,单例模式,简单场景下使用,性能较高。
- ReentrantLock:适用于复杂场景,如高并发,需要公平锁、可中断、超时获取或多个条件变量等场景。
- 注意事项
- synchronized: 无需手动释放锁,异常时会自动释放锁,代码块优先级高于方法
- ReentrantLock: 需要手动释放锁,finally 块中释放锁,条件变量不易过多使用,影响性能
线程池
ThreadLocal
参考
微服务
- 怎么理解微服务
- 微服务的缺点
- 对比微服务和传统服务的优缺点
- 微服务之间怎么做负载均衡
Spring
如何解决循环依赖问题?
AOP
AOP 是什么?
答:AOP(Aspect-Oriented Programming,面向切面编程) 能够将那些与业务无关, 却为业务模块所共同调用的逻辑或责任(例如事务处理、日志管理、权限控制等)封装起来, 便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可拓展性和可维护性。
- 著作权归 JavaGuide(javaguide.cn)所有
- 基于 MIT 协议
- 原文链接:https://javaguide.cn/system-design/framework/spring/spring-design-patterns-summary.html
IOC
IOC 是什么?
答:IoC(Inversion of Control,控制反转) 是 Spring 中一个非常非常重要的概念,它不是什么技术,而是一种解耦的设计思想。 IoC 的主要目的是借助于“第三方”(Spring 中的 IoC 容器) 实现具有依赖关系的对象之间的解耦(IOC 容器管理对象,你只管使用即可),从而降低代码之间的耦合度。
- 著作权归 JavaGuide(javaguide.cn)所有
- 基于 MIT 协议
- 原文链接:https://javaguide.cn/system-design/framework/spring/spring-design-patterns-summary.html
设计模式
单例设计模式 (Singleton Pattern)
详见 helltractor blog 中单例模式
工厂设计模式 (Factory Pattern)
Spring 中的 BeanFactory 和 ApplicationContext 就是工厂模式的体现,它们用来创建和管理对象。
- BeanFactory:延迟注入(使用到某个 bean 的时候才会注入),相比于 ApplicationContext 来说会占用更少的内存,程序启动速度更快。
- ApplicationContext:容器启动的时候,不管你用没用到,一次性创建所有 bean 。BeanFactory 仅提供了最基本的依赖注入支持, ApplicationContext 扩展了 BeanFactory ,除了有 BeanFactory 的功能还有额外更多功能,所以一般开发人员使用 ApplicationContext 会更多。
- 著作权归 JavaGuide(javaguide.cn)所有
- 基于 MIT 协议
- 原文链接:https://javaguide.cn/system-design/framework/spring/spring-design-patterns-summary.html
代理设计模式 (Proxy Pattern)
TODO
适配器设计模式 (Adapter Pattern)
TODO
装饰器设计模式 (Decorator Pattern)
如 python 中的装饰器@cache,@lru_cache 等,可以在不改变原有代码的情况下,增加新的功能
观察者设计模式 (Observer Pattern)
TODO
模板方法设计模式 (Template Method Pattern)
如 jdbcTemplate,hibernateTemplate 之类,使用时只需要继承模板类,实现部分方法即可
消息队列
- 使用 MQ 的好处
- MQ 解耦和微服务解耦的区别
- MQ 的消息怎么保证不丢失
发生消息堆积怎么处理
答:从生产端、消费端、队列本身入手, 消费端增加消费者, 生产端做一个回调缓冲(如果太多减少消息生产), 队列进行消息压缩(我具体是说很多消息的 id 等属性重复在业务上可以接受压缩成一条)
Kafka
- Kafka 的基本原理
Kafka 的延迟队列是怎么实现的
答:Java 本身用延迟阻塞队列来接数据,面试官引导这样会造成每个机器都需要部署, 如果是分布式环境是不是需要分布式延迟队列, 我说是
RocketMQ
- RocketMQ 的延迟队列是怎么实现的
计算机基础
计算机网络
- https 建立连接的过程(SSL/TLS 协商的过程)
- 对称加密和非对称加密的优缺点
Cookie 和 Session
- cookie 和 session 的区别
操作系统
- 为什么要区分内核态和用户态
- 什么时候从用户态切换到内核态
- 你编程的情况下,系统调用什么时候会发生
数据库
索引
索引的优缺点
- 优点:
- 大大加快数据的检索速度(减少检索的数据量),减少磁盘 I/O 次数。
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
- 缺点:
- 创建索引和维护索引要耗费时间,降低数据的维护速度。
- 索引需要占用物理空间,降低数据存储量。
索引的数据结构
常见的索引数据结构包括: Hash 表、二叉查找树(BST)、平衡二叉查找树(AVL)、红黑树、B 树 和 B+ 树等。
目前大部分数据库系统及文件系统都采用 B-Tree 或其变种 B+Tree 作为索引结构。
B 树和 B+树两者有何异同呢?使用 B+树的好处?
B 树和 B+ 树都是多路平衡查找树,即每个节点有多个子节点。B 树和 B+ 树的区别主要在于:
- B 树的所以节点存储键值,B+树的非叶子节点只存储键,只有叶子节点存储键值。
- B 树的叶子节点相互独立,B+树的叶子节点有一条引用链指向与它相邻的叶子节点。
- B 树的检索是范围内的每个节点做二分查找,可能无需遍历到叶子节点,B+树的检索是范围内的每个节点都要遍历到叶子节点。
- B 树的范围查询,首先找到要查找的下限,然后进行中序遍历,直到找到上限;B+树的范围查询,只需对叶子节点进行遍历。
综上,B+ 树的优点在于,具有更少的 IO 次数,更稳定的查询效率,更适合范围查询。
什么是聚簇索引和非聚簇索引(底层存储方式)?
- 聚簇索引(聚集索引):索引结构和数据一起存放的索引,InnoDB 中的主键索引就属于聚簇索引。准确来说,是将数据存储在叶子节点中。
- 非聚簇索引(非聚集索引):索引结构和数据分开存放的索引,二级索引(辅助索引)就属于非聚簇索引。MySQL 的 MyISAM 引擎,不管主键还是非主键,使用的都是非聚簇索引。在叶子节点中存储叶子节点本身的索引值和主键值 (MyISAM 中存放是数据的地址值),有了主键值再进行一次回表操作,从聚簇索引中根据主键值定位数据位置。
什么是覆盖索引和联合索引?
- 覆盖索引即需要查询的字段正好是索引的字段,那么直接根据该索引,就可以查到数据了,而无需回表查询。
- 使用表中的多个字段创建索引,就是 联合索引,也叫 组合索引 或 复合索引。
在 InnoDB 存储引擎中,非主键索引的叶子节点包含的是主键的值。这意味着,当使用非主键索引进行查询时, 数据库会先找到对应的主键值,然后再通过主键索引来定位和检索完整的行数据。这个过程被称为“回表”。
什么是最左前缀匹配原则?
最左前缀匹配原则指的是在使用联合索引时,MySQL 会根据索引中的字段顺序,从左到右依次匹配查询条件中的字段。 如果查询条件与索引中的最左侧字段相匹配,那么 MySQL 就会使用索引来过滤数据,这样可以提高查询效率。
最左匹配原则会一直向右匹配,直到遇到范围查询(如 >、<)为止。对于 >=、<=、BETWEEN 以及前缀匹配 LIKE 的范围查询,不会停止匹配。
那些情况适合创建索引的?
- 不为 NULL 的字段: 索引字段的数据应该尽量不为 NULL,因为对于数据为 NULL 的字段,数据库较难优化。 如果字段频繁被查询,但又避免不了为 NULL,建议使用 0,1,true,false 这样语义较为清晰的短值或短字符作为替代。
- 被频繁查询的字段: 我们创建索引的字段应该是查询操作非常频繁的字段。
- 被作为条件查询的字段: 被作为 WHERE 条件查询的字段,应该被考虑建立索引。
- 频繁需要排序的字段: 索引已经排序,这样查询可以利用索引的排序,加快排序查询时间。
- 被经常频繁用于连接的字段: 经常用于连接的字段可能是一些外键列,对于外键列并不一定要建立外键, 只是说该列涉及到表与表的关系。对于频繁被连接查询的字段,可以考虑建立索引,提高多表连接查询的效率。
事务管理
事务的四大特性
事务是一组操作的集合,要么全部执行成功,要么全部回滚。事务的 ACID 特性包括:
- 原子性(Atomicity):事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
- 一致性(Consistency):执行事务前后,数据保持一致,例如转账业务中,无论事务是否成功,转账者和收款人的总额应该是不变的;
- 隔离性(Isolation):并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
- 持久性(Durability):一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
并发事务可能出现的问题
- 脏读:一个事务读取到另一个事务未提交的数据。
- 不可重复读:一个事务多次读取同一数据,但在读取过程中,另一个事务修改了数据,导致多次读取的数据不一致。
- 幻读:一个事务读取到另一个事务插入的数据,导致多次读取的数据不一致。
- 丢失修改:两个事务同时读取同一数据,其中一个事务修改了数据,另一个事务也修改了数据,导致其中一个事务的修改被覆盖。
不可重复读和幻读的区别在于:
- 不可重复读的重点是内容修改或者记录减少比如多次读取一条记录发现其中某些记录的值被修改;
- 幻读的重点在于记录新增比如多次执行同一条查询语句(DQL)时,发现查到的记录增加了。
什么是事务的隔离级别?
SQL 标准定义了四种事务隔离级别,不同的隔离级别对并发事务的影响不同,包括:
- 读未提交(Read Uncommitted,RU):允许脏读,一个事务可以读取到另一个事务未提交的数据。
- 读已提交(Read Committed,RC):只能读取到已提交的数据,避免脏读,但可能出现不可重复读。
- 可重复读(Repeatable Read,RR):保证同一事务中多次读取的数据是一致的,除非数据是被本身事务自己修改的。
- 串行化(Serializable):最高隔离级别,保证事务串行执行,避免脏读、不可重复读和幻读。
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交 | ✅ | ✅ | ✅ |
| 读已提交 | ❌ | ✅ | ✅ |
| 可重复读 | ❌ | ❌ | ✅ |
| 串行化 | ❌ | ❌ | ❌ |
MySQL InnoDB 存储引擎默认的隔离级别是可重复读(Repeatable Read)。采用以下方式解决幻读问题的发生:
- 快照读:在可重复读隔离级别下,通过 MVCC 机制,读取到的是快照数据,不会受到其他事务的影响。
- 当前读:使用 Next-Key Lock 进行加锁来保证不出现幻读,Next-Key Lock 是行记录锁(Record Lock)和间隙锁(Gap Lock)的结合,行锁只能锁住已经存在的行,为了避免插入新行,需要依赖间隙锁。
解决幻读的方法
- 升级事务隔离级别:将隔离级别升级到 Serializable,保证事务串行执行,避免幻读。
- 使用锁机制:Next-Key Lock,保证不会出现幻读。
锁机制
锁的分类与类型
- 锁的粒度
- 行锁
- 记录锁(Record Lock):属于单个行记录上的锁。
- 间隙锁(Gap Lock):锁定一个范围,不包括记录本身。
- 临键锁(Next-Key Lock):Record Lock+Gap Lock,锁定一个范围,包含记录本身,主要目的是为了解决幻读问题(MySQL 事务部分提到过)。记录锁只能锁住已经存在的记录,为了避免插入新记录,需要依赖间隙锁。
- 表锁
- 页锁:锁定数据页
- 行锁
- 锁的类型
- 共享锁(S 锁):又称读锁,事务在读取记录的时候获取共享锁,允许多个事务同时获取(锁兼容)。
- 排他锁(X 锁):又称写锁/独占锁,事务在修改记录的时候获取排他锁,不允许多个事务同时获取。如果一个记录已经被加了排他锁,那其他事务不能再对这条事务加任何类型的锁(锁不兼容)。
- 意向锁(表锁)
- 意向共享锁(Intention Shared Lock,IS 锁):事务有意向对表中的某些记录加共享锁(S 锁),加共享锁前必须先取得该表的 IS 锁。
- 意向排他锁(Intention Exclusive Lock,IX 锁):事务有意向对表中的某些记录加排他锁(X 锁),加排他锁之前必须先取得该表的 IX 锁。
什么是死锁?如何避免死锁?
死锁是指两个或两个以上的事务之间互相等待对方具有的锁,同时持有对方需要的锁。
- 避免死锁
- 控制资源获取顺序:事务按照一定顺序获取一系列锁,获取不到释放当前占有的锁。
- 控制锁的粒度或少用锁:通过将隔离等级从 RR 更改为 RC,避免间隙锁和 next-key 锁带来的死锁情况。
- 减少持有资源的时间:事务具有长时间锁的需求,可以将 SQL 语句集中在事务的最前面或最后面。
- 解决死锁
- 目前的数据库都一般都具备自动干预死锁的能力。比如 mysql 中可以通过同等待图机制检测到死锁后选择回滚一个开销较小的事务来解决死锁; 还可以通过设置一个事务的超时时间来避免死锁;
- 事务隔离级别与锁的关系
什么是乐观锁和悲观锁?如何实现?
数据库优化
- 数据库结构优化
- MySQL 数据库 CPU 使用率飙升的原因
- 为什么要分库分表
- 分库分表的具体实施策略
- 分库分表存在那些问题
- 什么是 MySQL 主从复制
- MySQL 主从复制的工作原理
- MySQL 读写分离的实现方案
MySQL
- MySQL 可以不指定主键建表吗,背后的逻辑是什么
- 聚簇索引和其他索引有什么区别
- 建唯一索引,插入数据时是怎么处理的
- 重复插入会报错,是怎么处理的
- 不同事物隔离级别的实现
Explain 的作用是什么?
Explain 是 MySQL 提供的用于分析查询语句的工具,可以帮助开发人员分析查询语句的性能,找出可能存在的问题。
| 字段 | 说明 |
|---|---|
| id | 查询的序列号,表示查询中执行 select 子句或操作表的顺序 |
| select_type | 查询的类型,主要有:SIMPLE、PRIMARY、SUBQUERY、DERIVED、UNION、UNION RESULT 等 |
| table | 查询的表 |
| type | 查询的类型,主要有:system、const、eq_ref、ref、range、index、all 等 |
| possible_keys | 可能使用的索引 |
| key | 实际使用的索引 |
| key_len | 使用的索引的长度 |
| ref | 显示索引的哪一列被使用了,如果可能的话,是一个常数 |
| rows | MySQL 认为必顃读取的行数 |
| Extra | 额外的信息,包括不适合在其他列中显示但是还是重要的信息 |
Multi-Version Concurrency Control (MVCC)
MVCC 是如何实现的?
多版本并发控制(MVCC)通过保存数据的多个版本来实现并发控制,避免了读写冲突。
MVCC 的实现依赖于:隐藏字段、Read View、undo log。在内部实现中,InnoDB 通过数据行的 DB_TRX_ID 和 Read View 来判断数据的可见性, 如不可见,则通过数据行的 DB_ROLL_PTR 找到 undo log 中的历史版本。每个事务读到的数据版本可能是不一样的,在同一个事务中,用户只能看到该事务创建 Read View 之前已经提交的修改和该事务本身做的修改。
日志
MySQL 日志 主要包括错误日志、查询日志、慢查询日志、事务日志、二进制日志几大类。其中,比较重要的还要属二进制日志 binlog(归档日志)和事务日志 redo log(重做日志)和 undo log(回滚日志)。
redo log
- redo log 属于物理日志。
- redo log 是 InnoDB 存储引擎独有的,让 MySQL 拥有恢复崩溃的能力,保证数据的持久性。
- 写入机制:当对表数据进行更新时,首先查找 buffer pool,没有命中则从硬盘中以数据页的形式读取。事务执行时,redo log 通过记录“在某个数据页上做了什么修改”,写入 redo log buffer,事务提交时,判断是否刷盘到硬盘中的 redo.file。
- 存储形式:日志文件组,环形数组。
binlog
- binlog 属于逻辑日志。
- binlog 会记录所有涉及更新数据的逻辑操作,并且是顺序写。保证了 MySQL 集群架构的数据一致性。
- 写入机制:事务执行时,将 binlog 写入 binlog cache,事务提交时,判断是否刷盘到硬盘中的 binlog 文件中。
- 存储形式
- statement:具体 SQL 语句;
- row:具体 SQL 语句+具体数据;
- mixed:MySQL 会判断这条 SQL 语句是否可能引起数据不一致,如果是,就用 row 格式,否则就用 statement 格式。
undo log
- undo log 属于逻辑日志。
- undo log 保证事务原子性。
- 存储形式:undo log 记录的时 SQL 语句,是已经执行的语句对应的回溯语句。undo log 信息会记录再 redo log 中,因为 undo log 也要实现持久性保护。undo log 是采用 segment(段)的方式来记录的,每个 undo 操作在记录的时候占用一个 undo log segment,包含在 rollback segment 中。
- history list:history list 是 rollback segment header 的一部分,它的主要作用是记录所有已经提交但还没有被清理(purge)的事务的 undo log。这个列表使得 purge 线程能够找到并清理那些不再需要的 undo log 记录。
为什么需要两阶段提交?
为了保证逻辑日志和物理日志的一致性;如果没有二阶段提价的话;如果插入操作先提交了 redo log 此时 undo log 还没有进行写盘此时断电了;再次重启数据库后 bin log 就无法感知导致从数据库比主数据库少一条数据;如果先写入 bin log 再写入 redo log, 如果 bin log 完成写入后崩溃那么 redo log 就无法感知未记录的事务, 就会导致从数据中有这个事务但是主数据中没有。
- 作者:不吃勤菜_Java 版
- 链接:https://www.nowcoder.com/discuss/727194657410531328?sourceSSR=search
- 来源:牛客网
主从复制
TODO
缓存
缓存预热是什么
答:缓存预热是在业务刚上线的时候,我们最好提前把数据缓起来,而不是等待用户访问才来触发缓存构建,可采用后台更新机制。
超卖问题是什么,应该怎么解决?
以证券交易系统为例
- 超卖问题:在高并发交易场景下,撮合系统没有正确更新和同步库存数据,导致同一批股票被多次卖出。
- 根本原因:
- 并发问题:多个线程同时读取库存数据,判断库存充足后,同时更新库存。
- 缓存问题:缓存和数据库数据不一致,缓存数据未正确更新。
- 事务问题:事务未正确提交或回滚,导致库存数据未正确更新。
- 撮合引擎问题:撮合引擎处理顺序错误。
- 解决方案:
- 悲观锁:在更新库存时加锁,保证同一时间只有一个线程更新库存。
- 乐观锁:在更新库存时,先查询库存,再更新库存,保证库存不为负数。
- 消息队列:将用户的购买请求放入消息队列,异步处理,保证库存不为负数。
- 冻结库存:在用户下单时,先冻结库存,等订单撮合成功后再扣减库存。
- 内存泄露具体发生在哪
- 栈内存泄漏和堆内存泄漏的区别
Redis (Remote Dictionary Server)
- 购物车为什么用 Redis 存,是永久存储吗
- 为什么购物车多读多写
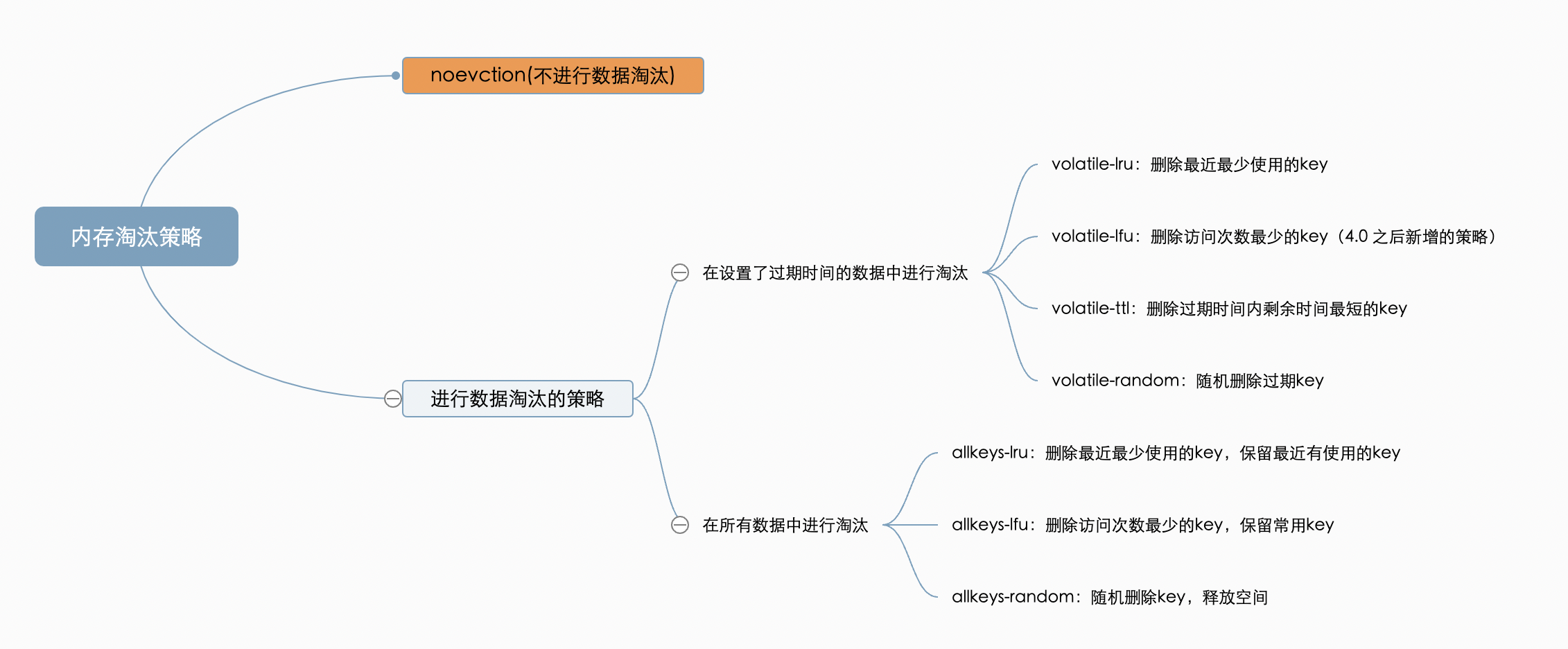
- Redis 怎样清除过期 key,有哪些策略
- 集群环境下,Redis 内存里的数据怎么保证一致
- 如何实现 Redis 的定时机制
Redis 有那些客户端,有什么区别?
- Jedis:是 Redis 官方推荐的 Java 客户端,基于连接池,线程安全。
- Lettuce:是一个高性能的 Redis 客户端,基于 Netty,支持异步和同步操作,线程安全。
- Redisson:是一个基于 Redis 的 Java 驻内存数据网格(In-Memory Data Grid)和分布式锁服务框架,提供了许多分布式对象和服务,如分布式集合、分布式对象、分布式锁、分布式服务等。
- Spring Data Redis:是 Spring Data 项目的一部分,提供了对 Redis 的支持,简化了 Redis 的操作,提供了 RedisTemplate 和 StringRedisTemplate 两个模板类。
Redis 为什么这么快?
Redis 之所以快,主要有以下几个原因:
- 基于内存:Redis 数据存储在内存中,读写速度快。
- 单线程:Redis 是单线程模型,避免了多线程的频繁上下文切换。
- 非阻塞 I/O:Redis 使用 epoll 作为 I/O 多路复用技术,非阻塞 I/O。
- 数据结构:Redis 使用了高效的数据结构,如哈希表、跳表、链表等。
- 持久化:Redis 支持 RDB 和 AOF 两种持久化机制,保证数据持久化。
- 集群:Redis 支持主从复制、哨兵和集群模式,提高了可用性和扩展性。
Redis 旁路缓存(Cache Aside)和写回缓存(Write Back)的区别
- 旁路缓存(Cache Aside):读取数据时,先从缓存中读取,如果缓存中没有数据,再从数据库中读取,然后将数据写入缓存。更新数据时,先更新数据库,再删除缓存。
- 写回缓存(Write Back):读取数据时与旁路缓存一致。更新数据时,先更新缓存,再更新数据库。
redis 怎么实现分布式锁,setnx 有哪些参数?
Redis 分布式锁 通常通过 SETNX(Set if Not Exists) 命令实现。
SET key value NX PX seconds- key:锁的标识值
- value:唯一标识,用于判断锁的归属
- NX:只在键不存在时,才对键进行设置操作
- PX seconds:设置键的过期时间,防止锁忘记释放
redisson 是怎么确定锁的拥有者的?
- 唯一标识:使用 UUID 作为 value 参数,设置唯一标识,用于判断锁的归属。
- 看门狗机制:leaseTime没有设置时,Redisson 会使用 30 秒作为默认的 leaseTime,同时启动一个看门狗线程,每隔 10 秒续期一次,避免锁过期。
- 可重入锁:同一线程多次加锁时,Redisson 会维护一个锁的重入计数器,避免阻塞。
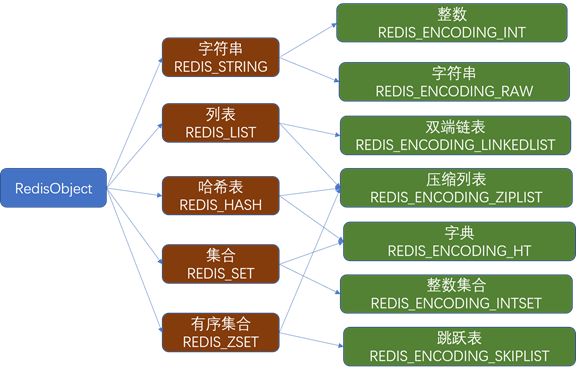
数据类型
Redis 支持多种数据类型:
- String:二进制安全字符串,最大 512MB。
- List:链表,支持左右插入/弹出操作。
- Set:无序集合,不允许重复元素,支持集合操作。
- Sorted Set:有序集合,元素按分数排序。
- Hash:哈希表,适合存储对象。
- Bitmap:位数组,处理位级别数据。
- HyperLogLog:基数统计,用于估算不重复元素数量。
- Stream:日志型数据结构,适用于日志和消息队列场景。
持久化机制
Redis 支持两种持久化机制:
- RDB(Redis DataBase):定期将数据快照保存到磁盘,适合大数据集的冷备份。
- AOF(Append Only File):记录每个写操作的日志文件,恢复时重放日志文件,数据更持久。
数据类型 (database type)
- Redis 底层怎么实现的
- hashtable 是怎样实现的
- ziplist 怎样实现的
- 普通的哈希表怎样实现的
- 哈希表怎么扩容
参考
内存三剑客
没获取到锁的线程怎么处理?
- 重试机制,等待一段时间后再次尝试获取锁,或使用指数退避算法
- 直接抛出异常提示用户稍后再试
- 如果缓存中有逻辑过期时间,可以在锁争抢失败时直接返回过期数据,同时后台异步更新
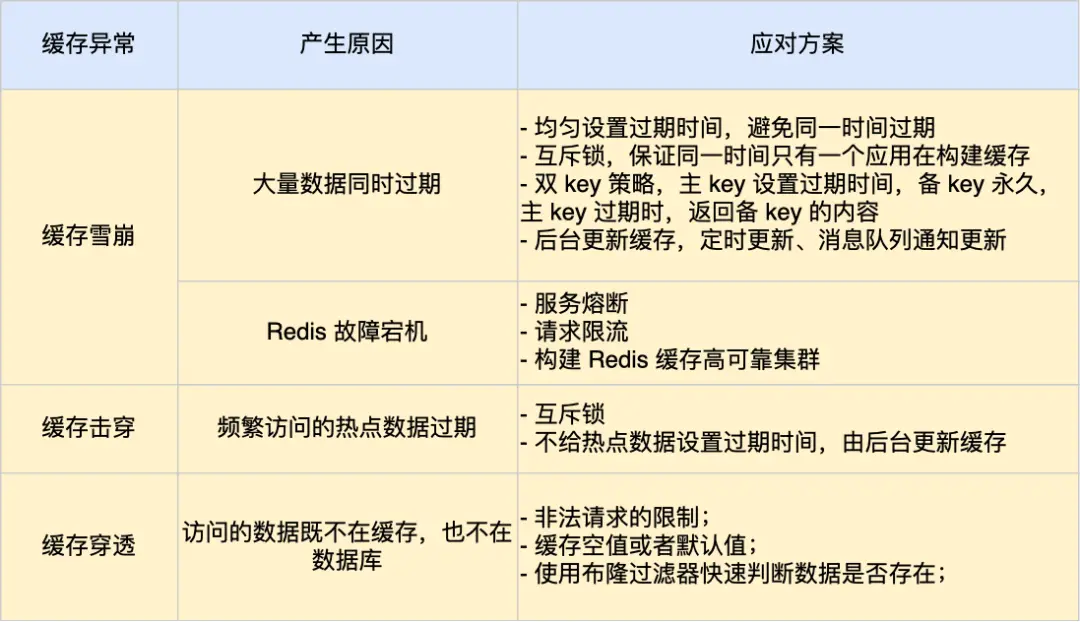
内存穿透
- 现象:请求访问缓存和数据库中都不存在的 key,每次请求都会直接达到数据库,导致数据库压力激增
- 解决方案:
- 布隆过滤器:将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据会被这个 bitmap 拦截掉
- 空值过滤:缓存层增加一个空值的标记,当存储层没有数据时,缓存层也会将这个空值标记存入缓存,但是会设置一个较短的过期时间(TTL)
- 限流保护:对异常频繁的请求进行 IP 或验证码的验证
内存击穿
- 现象:某个热点 key 过期,大量并发请求同时访问数据库,导致数据库瞬间承受高负载
- 解决方案:
- 互斥锁:保证同一时间只有一个业务线程更新缓存,未能获取互斥锁的请求,要么等待锁释放后重新读取缓存,要么直接返回空值或默认值
- 后台更新缓存:不给热点数据设置过期时间,由后台线程异步更新缓存,或者在在热点数据准备要过期前,提前通知后台线程更新缓存以及设置过期时间
内存雪崩
- 现象:缓存层的大量数据同时过期,导致请求直接访问数据库,数据库压力激增
- 解决方案:
- 缓存集群+数据库集群:通过多台机器部署缓存和数据库,提高系统的容错性
- 随机过期时间:缓存数据的过期时间设置随机值,防止同一时间大量数据过期现象
- 互斥锁:锁住更新缓存的资源,保证只有一个线程去更新缓存,并设置锁的超时时间
- 后台更新缓存(缓存预热):业务线程不负责更新缓存,而是由后台线程负责定时更新缓存,或者在业务线程发现缓存过期时异步更新缓存
小结
参考
缓存策略
更新数据库+更新缓存
- 先更新数据库,再更新缓存和先更新缓存,再更新数据库:都存在并发问题,当两个请求并发更新同一条数据时,可能会出现缓存和数据库数据不一致的情况
- 解决方案:
- 分布式锁:保证同一时间只有一个线程更新缓存,其他线程等待锁释放后再更新缓存
- TTL:设置缓存的过期时间,保证缓存数据在一定时间内有效,过期后再更新缓存
更新数据库+删除缓存
- 先删除缓存,在更新数据库:读策略和写策略并发时,可能会出现缓存和数据库数据不一致的情况
- 解决方案:
- 延迟双删:设置一个延迟时间,再次删除缓存,保证缓存和数据库数据一致
- 先更新数据库,再删除缓存:读策略和写策略并发时,不会出现缓存和数据库数据不一致的情况,因为缓存的写入远远快于数据库的写入;但是会出现删除缓存失败的情况
- 解决方案:
- 消息队列重试机制:消息队列来重试缓存的删除,优点是保证缓存一致性的问题,缺点会对业务代码入侵
- 订阅 MySQL binlog,再操作缓存:订阅 MySQL binlog + 消息队列 + 重试缓存的删除,优点是规避了代码入侵问题,也很好的保证缓存一致性的问题,缺点就是引入的组件比较多,对团队的运维能力比较有高要求
反问
- 业务,开发语言,表现,对应届生的要求(重点是基础和算法)
- 部门怎样培养新人,刚进来做什么(学基础,语言和中间件,做 demo),大概多久做需求(1 周到 1 个月不等,看学习情况),框架和中间件以开源的为主还是以自研的为主(自研的)
- 面试通过还有面试吗,新人入职有培训吗,技术氛围怎么样
场景
鉴权
- Oauth2 基本流程、原理
- 登录模块是怎么做的
介绍一下 jwt,他是怎么加密的?
JWT 由三部分组成,如Header.Payload.Signature。
- Header:头部,通常由两部分组成,令牌的类型(即 JWT)和所使用的加密算法(如 HMAC SHA256 或 RSA)。
- Payload:负载,包含声明,如用户信息、权限等。
- Signature:签名,由头部、负载和密钥生成,用于验证令牌是否被篡改。
通常说的JWT是没有第三方安全保障的,只是一个编码的字符串,可以通过base64解码得到明文信息。 常用的是JWS(JSON Web Signature),通过HMAC SHA256或RSA等算法生成签名,用于验证令牌是否被篡改。
graph LR
A[Header] --> |Base64| A1[encodeHeader]
B[Payload] --> |Base64| B1[encodeClaims]
A1 --> C[Concatenated]
B1 --> C
C --> D[SecretKey]
D --> |HMAC/SHA256| E[Signature]
E -->|SecretKey| F((Verify)){
"alg": "HS256",
"typ": "JWT"
}{
"sub": "1234567890",
"name": "John Doe",
"admin": true
}HMACSHA256(
base64UrlEncode(Header) + "." +
base64UrlEncode(Payload),
Secret
)jwt 和传统的 cookie+session 有什么区别呢?
| 特点 | JWT | Cookie + Session |
|---|---|---|
| 存储位置 | 客户端(通常在 LocalStorage) | 服务端存储 Session 数据 |
| 状态管理 | 无状态(Stateless) | 有状态(Stateful) |
| 扩展性 | 更好,适合分布式系统 | 依赖服务器的内存或数据库 |
| 安全性 | 容易被拦截,需要配合 HTTPS 使用 | SessionID 可泄露,容易被劫持 |
| 性能 | 不需要查询数据库即可验证 | 需要数据库或 Redis 查询验证 |
| 注销和撤销 | 无法立即撤销,需要等待过期 | 可直接删除 Session |
云存储
为什么用 oss 存储,怎么不直接存在本地服务器?
OSS(Object Storage Service),对象存储服务。对于非结构性文件,OSS 比本地存储更加可靠,更加经济。
杂
做项目的过程中遇到过什么问题,怎么解决的
介绍一下线程安全的类
| 类别 | 类名 | 说明 |
|---|---|---|
| 基础类 | String, StringBuffer, AtomicInteger | StringBuffer 使用了同步方法,线程安全 |
| 集合类 | Vector, ConcurrentHashMap, CopyOnWriteArrayList | 使用同步或锁机制保证线程安全 |
| 工具类 | Collections.synchronizedList | 通过包装实现线程安全的集合 |
| Blocking 队列 | LinkedBlockingQueue, ArrayBlockingQueue | 支持生产者-消费者模型,线程安全 |
| 原子类 | AtomicInteger, AtomicLong, AtomicReference | 使用 CAS(Compare And Swap)实现原子操作 |
Netty
- Netty 为什么高性能?