Redis (Remote Dictionary Server)
数据类型
基础概念
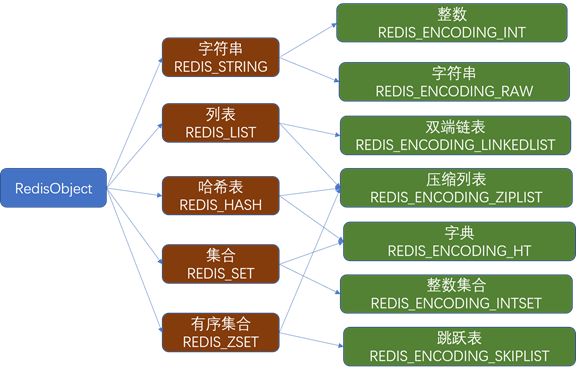
Redis 支持多种数据类型,每种类型都基于不同的底层数据结构实现,适用于不同的业务场景。
- 字符串(REDIS_STRING):适用于 缓存、计数、共享 Session、IP 统计、分布式锁等。
- 列表(REDIS_LIST): 链表、消息队列、栈、有序的对象列表(如朋友圈的点赞顺序列表、评论顺序列表)。
- 哈希表(REDIS_HASH): 购物车信息、用户信息、Hash 类型的 (key, field, value) 存储对象等。
- 集合(REDIS_SET):无序的唯一的键值结构: 好友、关注、粉丝、感兴趣的人集合等。
- 有序集合(REDIS_ZSET):访问排行榜、点赞排行、粉丝数排行等。
常见问题
Redis 底层怎么实现的?
Redis 的五种数据类型都有多种底层编码实现:
"String 类型:int、embstr、raw 三种编码,根据内容和长度自动选择 Hash 类型:ziplist 和 hashtable,小数据用 ziplist 节省内存 List 类型:使用 quicklist,结合了 ziplist 和 linkedlist 的优点 Set 类型:intset 和 hashtable,整数集合用 intset 优化 ZSet 类型:ziplist 和 skiplist+hash,跳跃表支持高效范围查询 这种设计在保证功能的同时,针对不同场景进行了内存和性能优化。"
- hashtable 是怎样实现的
- ziplist 怎样实现的
IO 模型
基础概念
Redis 使用的是 I/O 多路复用模型,多路复用指的是:多个 socket 连接复用一个线程。这种模式下,内核不会去监视应用程序的连接,而是监视文件描述符。当客户端发起请求的时候,会生成不同事件类型的套接字。
而在服务端,因为使用了 I/O 多路复用技术,所以不是阻塞式的同步执行,而是将消息放入 socket 队列(参考下图的 I/O Multiplexing module),然后通过 File event Dispatcher 将其转发到不同的事件处理器上,如 accept、read、send。
持久化机制
基础概念
Redis 支持两种持久化机制:
RDB(Redis DataBase)Snapshot: Redis 在指定的时间间隔内,将内存中的数据集快照定格下来,写入磁盘,并存储在副本文件中。当 Redis 重启时,这些快照文件会被自动读取并恢复到内存中。
- **SAVE:**阻塞式保存,Redis 会阻塞所有的请求,直到 RDB 文件生成完成。
- **BGSAVE:**非阻塞式保存,Redis 会 fork 一个子进程来生成 RDB 文件,主进程继续处理请求。
- 优点:以二进制格式+数据压缩的方式存储数据,节省空间;恢复速度快。
- 缺点:无法实时持久化,每次创建子进程,频繁操作磁盘,性能开销大;数据丢失风险,如果 Redis 在 RDB 文件生成完成之前崩溃,则会丢失所有未保存的数据;无法兼容新旧版本 rdb 文件。
AOF(Append Only File):
以独立日志的方式存储了 Redis 服务器的顺序指令序列,并只记录对内存进行修改的指令。
- 优点:实时持久化,数据丢失风险小;支持增量备份;可以使用 Redis 的命令行工具进行查看和编辑。
- 缺点:AOF 文件体积较大,恢复速度慢;性能开销大;需要定期重写 AOF 文件。
- 重写机制:Redis 会在后台异步重写 AOF 文件,避免阻塞主线程。重写时,Redis 会 fork 一个子进程(分配内存)创建一个新的 AOF 文件,父进程将增量命令继续写入旧的 AOF 文件和 AOF 重写缓冲区,当子进程旧的 AOF 文件重写完毕,父进程再将重写缓冲区中的增量命令追加到新的 AOF 文件中,然后将旧的 AOF 文件替换为新的 AOF 文件。
混合持久化: RDB + AOF,就是在 AOF 重写 时,把当前数据快照 + 后续写入命令 一起保存到 AOF 文件里。
注意事项
- 重写时,当前写入命令会缓存到 auf_rewrite_buf 中,等到重写完成后,再将 auf_rewrite_buf 中的命令写入新的 AOF 文件中。
- RDB 提供了快照模式,记录某个时间的 Redis 内存状态。RDB 设计了 bgsave 和写时复制,尽可能避免执行快照期间对读写指令的影响,但是频繁快照会给磁盘带来压力以及 fork 阻塞主线程。需把握频率。
- AOF 日志存储了 Redis 服务的顺序指令序列,通过重放(replay)指令来写入日志文件,并通过写回策略来避免高频读写给 Redis 带来压力。
- RDB 快照的照片时间间隔,必然会带来数据缺失,如果允许分钟级别的数据丢失,可以只使用 RDB。
- 如果只用 AOF,写回策略优先使用 everysec 的配置选项,因为它在可靠性和性能之间取了一个平衡。
- 数据不能丢失时,内存快照和 AOF 的混合使用是一个很好的选择。
常见问题
Redis 又快有能持久化,那所有数据都放在 Redis 中可行吗?
通常情况下,我们会选择数据库对数据进行存储(如 MySQL、PostgreSQL),因为它们支持事务、表结构约束、复杂查询等特性。Redis 尽管具备高性能和持久化能力,但并不适合替代数据库作为全量数据存储。 正常情况下,一般将 Redis 作为 缓存层 + 高频访问热数据存储,数据库作为最终的持久化存储层。 只有在对事务和一致性要求不高,且内存资源充足的业务中,才可能考虑 Redis 直接存储全量数据。
每天增长数据百万条,还能够把数据放 Redis 中吗?
在日新增百万级别的数据场景下,Redis 不能作为唯一存储,需要结合业务优化:
- 可以按照业务情况设置过期时间、内存淘汰策略、分片与集群等来限制内存占用情况。
- 冷热分离:如果需要长期保存数据,应该将数据先写入数据库,再将部分热点数据同步到 Redis。
参考
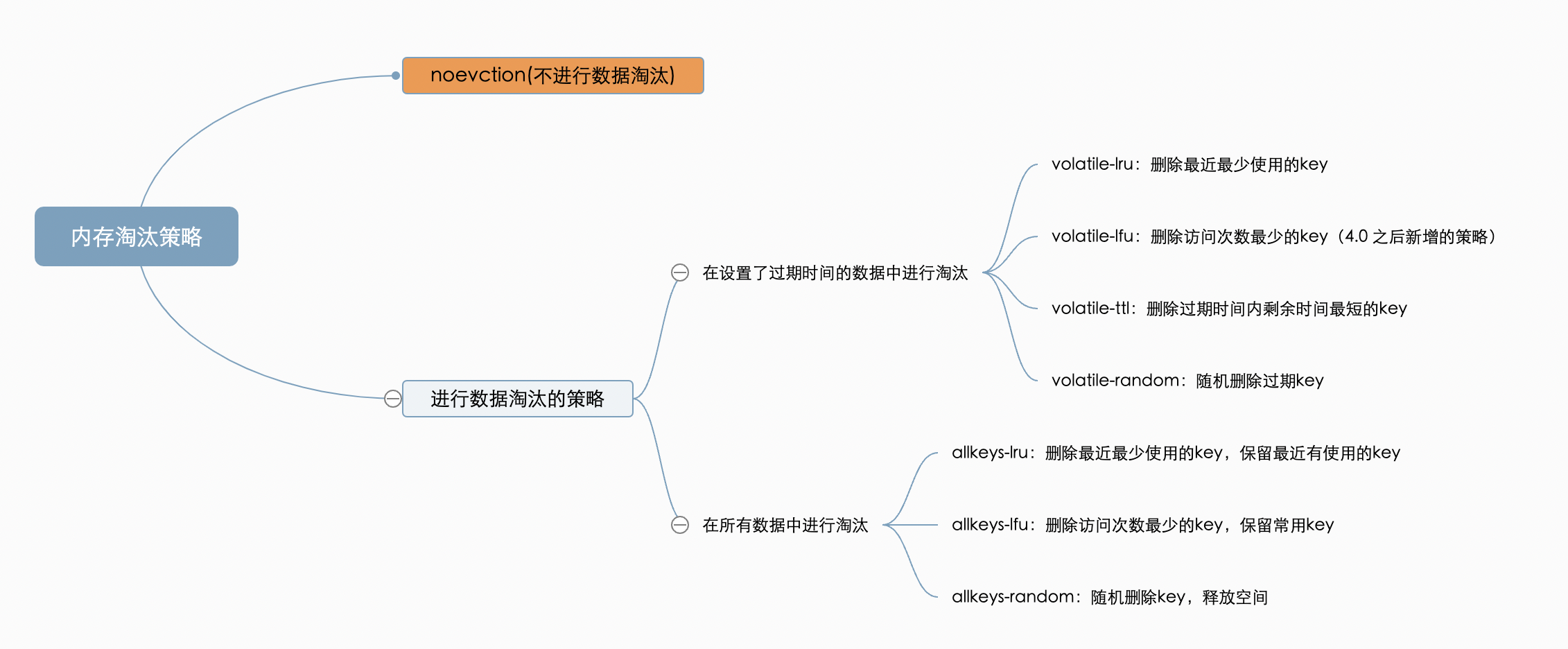
内存淘汰策略
内存淘汰策略是解决内存过大的问题,当 Redis 内存使用超过 maxmemory 限制时,Redis 会根据配置的淘汰策略来删除一些键值对,以释放内存。
常见问题
- 为什么购物车多读多写
- 集群环境下,Redis 内存里的数据怎么保证一致
- 如何实现 Redis 的定时机制
Redis 有那些客户端,有什么区别?
- Jedis:是 Redis 官方推荐的 Java 客户端,基于连接池,线程安全。
- Lettuce:是一个高性能的 Redis 客户端,基于 Netty,支持异步和同步操作,线程安全。
- Redisson:是一个基于 Redis 的 Java 驻内存数据网格(In-Memory Data Grid)和分布式锁服务框架,提供了许多分布式对象和服务,如分布式集合、分布式对象、分布式锁、分布式服务等。
- Spring Data Redis:是 Spring Data 项目的一部分,提供了对 Redis 的支持,简化了 Redis 的操作,提供了 RedisTemplate 和 StringRedisTemplate 两个模板类。
Redis 的主从复制原理?
Redis 主从复制有全量复制和部分复制两种方式。第一次连接或主库内存丢失时,会触发全量复制,主库生成 RDB 文件并发送给从库; 断线重连时,如果 offset 在主库复制缓冲区中还能找到,就会触发部分复制,只同步这段缺失的数据,避免了大规模数据传输,提高了系统的可用性。
Redis 的过期策略?
Redis 的过期策略主要有三种:
- 定时删除:Redis 会在设置过期时间时,使用定时器定期检查过期的键值对,并删除它们。
- 惰性删除:Redis 在访问键值对时,会检查该键值对是否过期,如果过期则删除它。
- 定期删除:Redis 会定期随机抽取一些键值对,检查它们是否过期,如果过期则删除它们。
Redis 使用的过期删除策略是惰性删除+定期删除,删除的对象是已过期的 key。
Redis 为什么这么快?
Redis 之所以快,主要有以下几个原因:
- 基于内存:Redis 数据存储在内存中,读写速度快。
- 单线程:Redis 是单线程模型,避免了多线程的频繁上下文切换。
- 非阻塞 I/O:Redis 使用 epoll 作为 I/O 多路复用技术,非阻塞 I/O。
- 数据结构:Redis 使用了高效的数据结构,如哈希表、跳表、链表等。
- 持久化:Redis 支持 RDB 和 AOF 两种持久化机制,保证数据持久化。
- 集群:Redis 支持主从复制、哨兵和集群模式,提高了可用性和扩展性。
换而言之,Redis 是单线程模型,这样避免的多线程的上下文切换和锁竞争问题,同时通过非阻塞 I/O 和事件驱动模型来处理高并发请求。 另外数据存储在内存中,读写速度快,使用高效的数据结构,如哈希表、跳表、链表等,保证了数据的高效存取。
Redis 旁路缓存(Cache Aside)和写回缓存(Write Back)的区别
- 旁路缓存(Cache Aside):读取数据时,先从缓存中读取,如果缓存中没有数据,再从数据库中读取,然后将数据写入缓存。更新数据时,先更新数据库,再删除缓存。
- 写回缓存(Write Back):读取数据时与旁路缓存一致。更新数据时,先更新缓存,再更新数据库。
redis 怎么实现分布式锁,setnx 有哪些参数?
Redis 分布式锁 通常通过 SETNX(Set if Not Exists) 命令实现。
SET key value NX PX seconds- key:锁的标识值
- value:唯一标识,用于判断锁的归属
- NX:只在键不存在时,才对键进行设置操作
- PX seconds:设置键的过期时间,防止锁忘记释放
redisson 是怎么确定锁的拥有者的?
- 唯一标识:使用 UUID 作为 value 参数,设置唯一标识,用于判断锁的归属。
- 看门狗机制:leaseTime 没有设置时,Redisson 会使用 30 秒作为默认的 leaseTime,同时启动一个看门狗线程,每隔 10 秒续期一次,避免锁过期。
- 可重入锁:同一线程多次加锁时,Redisson 会维护一个锁的重入计数器,避免阻塞。
缓存
缓存预热是什么
答:缓存预热是在业务刚上线的时候,我们最好提前把数据缓起来,而不是等待用户访问才来触发缓存构建,可采用后台更新机制。
超卖问题是什么,应该怎么解决?
以证券交易系统为例
- 超卖问题:在高并发交易场景下,撮合系统没有正确更新和同步库存数据,导致同一批股票被多次卖出。
- 根本原因:
- 并发问题:多个线程同时读取库存数据,判断库存充足后,同时更新库存。
- 缓存问题:缓存和数据库数据不一致,缓存数据未正确更新。
- 事务问题:事务未正确提交或回滚,导致库存数据未正确更新。
- 撮合引擎问题:撮合引擎处理顺序错误。
- 解决方案:
- 悲观锁:在更新库存时加锁,保证同一时间只有一个线程更新库存。
- 乐观锁:在更新库存时,先查询库存,再更新库存,保证库存不为负数。
- 消息队列:将用户的购买请求放入消息队列,异步处理,保证库存不为负数。
- 冻结库存:在用户下单时,先冻结库存,等订单撮合成功后再扣减库存。
- 内存泄露具体发生在哪
- 栈内存泄漏和堆内存泄漏的区别
缓存三剑客
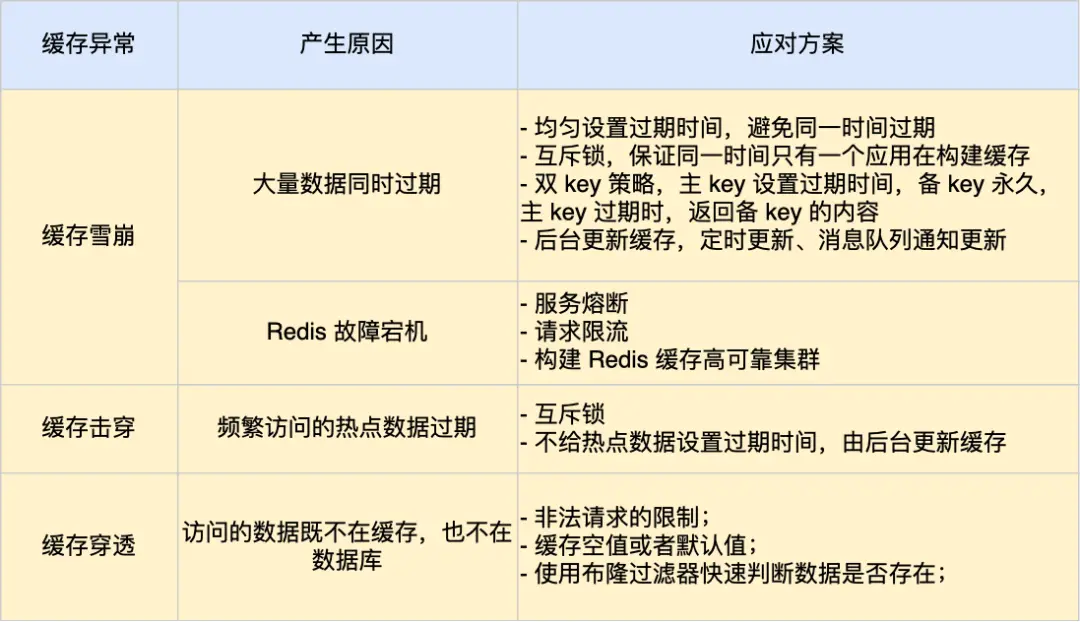
缓存穿透
- 现象:请求访问缓存和数据库中都不存在的 key,每次请求都会直接达到数据库,导致数据库压力激增
- 解决方案:
- 布隆过滤器:将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据会被这个 bitmap 拦截掉
- 空值过滤:缓存层增加一个空值的标记,当存储层没有数据时,缓存层也会将这个空值标记存入缓存,但是会设置一个较短的过期时间(TTL)
- 限流保护:对异常频繁的请求进行 IP 或验证码的验证
缓存击穿
- 现象:某个热点 key 过期,大量并发请求同时访问数据库,导致数据库瞬间承受高负载
- 解决方案:
- 互斥锁:保证同一时间只有一个业务线程更新缓存,未能获取互斥锁的请求,要么等待锁释放后重新读取缓存,要么直接返回空值或默认值
- 后台更新缓存:不给热点数据设置过期时间,由后台线程异步更新缓存,或者在在热点数据准备要过期前,提前通知后台线程更新缓存以及设置过期时间
缓存雪崩
- 现象:缓存层的大量数据同时过期,导致请求直接访问数据库,数据库压力激增
- 解决方案:
- 缓存集群+数据库集群:通过多台机器部署缓存和数据库,提高系统的容错性
- 随机过期时间:缓存数据的过期时间设置随机值,防止同一时间大量数据过期现象
- 互斥锁:锁住更新缓存的资源,保证只有一个线程去更新缓存,并设置锁的超时时间
- 后台更新缓存(缓存预热):业务线程不负责更新缓存,而是由后台线程负责定时更新缓存,或者在业务线程发现缓存过期时异步更新缓存
常见问题
没获取到锁的线程怎么处理?
- 重试机制,等待一段时间后再次尝试获取锁,或使用指数退避算法
- 直接抛出异常提示用户稍后再试
- 如果缓存中有逻辑过期时间,可以在锁争抢失败时直接返回过期数据,同时后台异步更新
小结
参考
缓存策略
旁路缓存(Cache Aside)
- 读取数据:先从缓存中读取,如果缓存中没有数据,再从数据库中读取,然后将数据写入缓存
- 更新数据:先更新数据库,再同步更新或删除缓存
更新数据库+更新缓存
- 先更新数据库,再更新缓存和先更新缓存,再更新数据库:都存在并发问题,当两个请求并发更新同一条数据时,可能会出现缓存和数据库数据不一致的情况
- 解决方案:
- 分布式锁:保证同一时间只有一个线程更新缓存,其他线程等待锁释放后再更新缓存
- TTL:设置缓存的过期时间,保证缓存数据在一定时间内有效,过期后再更新缓存
更新数据库+删除缓存
- 先删除缓存,在更新数据库:读策略和写策略并发时,可能会出现缓存和数据库数据不一致的情况
- 解决方案:
- 延迟双删:设置一个延迟时间,再次删除缓存,保证缓存和数据库数据一致
- 先更新数据库,再删除缓存:读策略和写策略并发时,不会出现缓存和数据库数据不一致的情况,因为缓存的写入远远快于数据库的写入;但是会出现删除缓存失败的情况
- 解决方案:
- 消息队列重试机制:消息队列来重试缓存的删除,优点是保证缓存一致性的问题,缺点会对业务代码入侵
- 订阅 MySQL binlog,再操作缓存:订阅 MySQL binlog + 消息队列 + 重试缓存的删除,优点是规避了代码入侵问题,也很好的保证缓存一致性的问题,缺点就是引入的组件比较多,对团队的运维能力比较有高要求